Glue と Athena と Data Lake
1年ほど前に Amazon Athena がリリースされ、半年ほど前に AWS Glue や Redshift Spectrum がリリースされ、この1年で AWS のビッグデータ関連のサービスが次々と出てきました。
Athena や Glue は、それ単体でも十分に便利なのですが、データレイクの構成要素としてそれぞれ重要な役割を持っています。
この記事では、データレイクにとって Glue や Athena がどういう位置付けなのか考えてみようと思います。
データレイクとは?
Wikipedia では data lake は次のように説明されています。
A data lake is a method of storing data within a system or repository, in its natural format,[1] that facilitates the collocation of data in various schemata and structural forms, usually object blobs or files. The idea of data lake is to have a single store of all data in the enterprise ranging from raw data (which implies exact copy of source system data) to transformed data which is used for various tasks including reporting, visualization, analytics and machine learning. The data lake includes structured data from relational databases (rows and columns), semi-structured data (CSV, logs, XML, JSON), unstructured data (emails, documents, PDFs) and even binary data (images, audio, video) thus creating a centralized data store accommodating all forms of data.[2]
ざっくり要約すると、データレイクとは、構造化データに限らない様々な形式の生データから、分析や機械学習などに使いやすいように加工した整形済みデータまで、あらゆるデータを1箇所に集積する手法のことです。それにより、データレイク内に存在する非構造化データを含む様々なデータを組み合わせて利用することが容易になります。
よくある使い方としては、生ログを全てデータレイクに保存した後、必要なデータを抽出しきれいに整形した上でデータウェアハウスにロードする、などがあります。
AWS におけるデータレイク
AWS においては、S3 がデータレイクの役目を果たします。
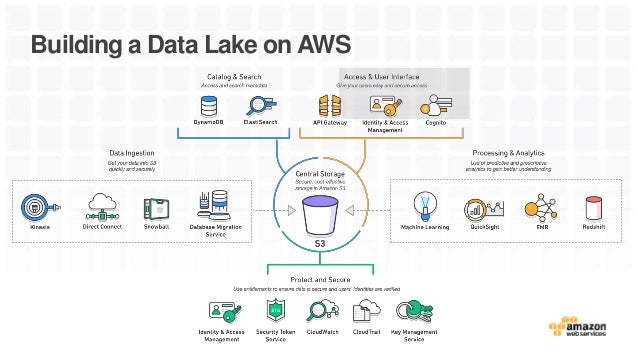
S3 をデータレイクとして使う場合は、次のような構成が一般的かと思います。
- Kinesis Firehose などで S3(=データレイク)にデータを流し込む。
- EMR を使いデータを抽出し、使いやすい形に整形する。
- 整形されたデータを Redshift や Presto にロードするなどして、BI ツールなどから参照できるようにする。
データレイクの生命線
データレイクのアイデアはとても単純で「あらゆるデータを1箇所に集める」それだけです。しかし、もう1つ重要な要素があります。
何も考えずにあらゆるデータをデータレイクに流し込んでしまうと、「どこに何のデータがあるのか分からない」状態になります。欲しいデータがどこに保存されているのか分からない、ここにあるデータが何のデータなのか分からない状態です。こうなってしまうと、データレイクから意味のある情報を取り出すことはできません。せっかくのデータがゴミの山になってしまいます。このようなデータレイクは "data swamp"(データの沼)と呼ばれるそうです。
Data lake を data swamp にしないために最も重要なのは、どこに何のデータがあるのかという情報 です。この情報は メタデータ と呼ばれます。メタデータは次のような情報を含みます。
- データに対する説明
- データの場所(S3 bucket と prefix)
- データのフォーマット(CSV, JSON, XML, raw data, ...)
- データのスキーマ(CSV のカラム名やJSONの構造など)
- データが保存されている場所のディレクトリ構造など
Hive on EMR で外部テーブルを使ったことがある方なら馴染みがあるかもしれません。Hive で外部テーブルを作成する際には、上に挙げたような情報を指定する必要があります。以下は、S3 上にある CSV ファイルに対して外部テーブルを作成する例です。
CREATE EXTERNAL TABLE csv_data ( -- データのスキーマ col_1 STRING, col_2 STRING ) -- データに対する説明 COMMENT '....' -- データの形式 ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' -- データの保存場所 LOCATION 's3://bucket/my-csv-data/'
これらの情報は hive metastore と呼ばれるデータベース(実体は MySQL)に保存されます。
メタデータの難しさ
データレイクを運用していくには、メタデータの管理が非常に重要になります。しかし、メタデータをきちんと管理するのは意外と大変です。
1つは、実データとメタデータを同期していく難しさです。データレイクにやってくるデータの形式は常に同じとは限りません。サービスに新機能が実装され、新しいフィールドが追加されるかもしれません。データ量を減らすため JSON から MessagePack に変更したくなる日が来るかもしれません。もっと辛い場合だと、オペレーションミスなどである時期だけ CSV のフィールドの順番が変わってしまうなんてこともあるかもしれません。実データの形式が変わるのに合わせてメターデータをアップデートしていく必要があります。
また、新しいデータソースに対応していくというタスクもあります。継続的に発生するデータの場合、特定の期間のデータを効率よく取得するために、データが発生した日付ごとにデータの保存場所を変えるのが一般的です。そうなると、毎日発生するデータの保存場所を日々メタデータに追加していく必要があります。さらに、今まで取得していなかったログを新たに取得し始めるなどして、データの種類が増える場合もあります。その場合は、新たなメタデータを作成する必要があります。
このように、メタデータを常に最新の状態に保つために、実データの変更や追加に常に気を配らなくてはいけません。データの種類が少ないうちはいいかもしれませんが、何種類ものデータが日々発生するようになって来ると、メタデータの運用はとても辛いものになります。
Glue とか Athena とか
AWS Glue (特に Glue Data Catalog)や Amazon Athena は、こうしたデータレイクやメタデータを運用していく上での課題を解決しようとしています。
Glue Data Catalog は、フルマネージドな Hive Metastore のサービスです。Glue Data Catalog は Hive の外部テーブルの情報を管理しています。Hive on EMR から Glue Data Catalog に接続することで、Glue Data Catalog で管理されている S3 上のデータに対して SQL でクエリを投げることができるようになります。Hive だけでなく、Spark や Redshift Spectrum など Hive Metastore に対応した製品であれば、Glue Data Catalog のテーブルを参照することができます。
Glue Data Catalog の便利な機能の1つにクローラーというものがあります。これは、Glue が S3 上に作成されるオブジェクトを監視して、新たに追加されたデータに対して自動でスキーマを検出しメタデータに追加してくれるというものです。これにより、メタデータの運用コストは大きく下げることができるかもしれません。
また、Amazon Athena はデータレイクの中を探索する際に非常に役に立ちます。Athena はフルマネージド Presto のサービスです。ブラウザから Athena のコンソールに行き SQL を打ち込むと Glue Data Catalog のテーブルに対してすぐにクエリを投げることができます。EMR のようにいちいちクラスタを立ち上げる必要はありません。
Glue Data Catalog で検出されたデータに対して Athena で即座に中身を確認する、といった使い方ができるようになるわけです。データレイクの中を気軽に歩き回ることができるようになり、data lake が data swamp になることを防ぐことができるのではないでしょうか。
(おまけ) BigQuery と Athena
最初、Athena のことは「AWS 版 BigQuery」くらいに思っていました。BigQuery に比べると、Athena は遅いし Parquet / ORC への変換は面倒だし、なんだかなあという印象でした。 ただ、こうしてデータレイクについて考えていくと、BigQuery と Athena は若干立ち位置が違うようです。
BigQuery の説明を見るとはっきりと「データウェアハウス」と書かれています。BI ツールと接続してどんな巨大なデータでもストレスなくサクサク見れることを目指しているのでしょうか。それに対して、Athena の説明はどこを探しても「データウェアハウス」という言葉はみつからず、「サーバーレスのインタラクティブなクエリサービス」と説明されています。Athena は、とにかく気軽にS3にクエリを投げられることを目指しているように思えます。
AWS のデータウェアハウスといえば Redshift。Athena と Redshift Spectrum の使い分けも迷うところですが、やはり Redshift / Redshift Spectrum はデータウェアハウスとしての性能を目指しているのでしょうね。
BigQuery と Athena と Redshift / Redshift Spectrum、似てるようでそれぞれ使い勝手も性能も違うので、用途に合ったものをきちんと選択したいものです。
まとめ
- データレイクはどこに何のデータがあるかわからなくなったら終わり。
- メタデータがデータレイクの生命線。だけど運用大変。
- Glue Data Catalog と Athena をうまく使うと幸せになれるかもね。